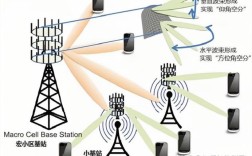
软件技术大数据技术应用已成为当今数字化时代的核心驱动力,深刻改变着各行各业的生产方式和决策模式,随着信息技术的飞速发展,数据量呈爆炸式增长,如何有效采集、存储、处理、分析这些数据,并将其转化为有价值的信息和知识,成为企业和社会发展的重要课题,软件技术作为大数据技术应用的基础支撑,提供了从数据产生到价值实现的全流程技术解决方案,二者相辅相成,共同推动着数字经济的蓬勃发展。
在数据采集与存储层面,软件技术为大数据提供了高效、可靠的技术手段,传统的数据库系统在处理海量、高并发、多样化的数据时显得力不从心,而以Hadoop、Spark为代表的分布式计算框架和NoSQL数据库(如MongoDB、Cassandra)的出现,彻底改变了数据存储和处理的格局,Hadoop分布式文件系统(HDFS)通过将数据分割成多个块存储在普通硬件上,实现了高容错性和高扩展性,成为大数据存储的基础设施,Kafka等消息队列技术能够实时、高吞吐地采集和传输数据流,为实时数据分析提供了数据源保障,在数据采集环节,爬虫技术、物联网传感器数据采集接口、企业应用系统数据对接等软件工具,确保了多源异构数据的全面获取,为后续分析奠定了坚实基础。
数据处理与计算是大数据应用的核心环节,软件技术通过分布式计算、内存计算、流计算等技术,实现了对海量数据的高效处理,MapReduce作为Hadoop的核心计算模型,通过“分而治之”的思想,将大规模数据处理任务分解为多个小任务并行执行,显著提高了处理效率,而Spark则基于内存计算,比MapReduce具有更高的迭代计算性能,适用于机器学习、图计算等复杂场景,随着实时性需求的增加,Flink、Storm等流计算框架应运而生,能够对实时数据流进行即时处理和响应,满足金融风控、实时推荐等场景的低延迟要求,数据清洗、数据转换、数据集成等ETL工具(如Apache NiFi、Talend),通过可视化的操作界面,简化了数据预处理流程,确保了数据质量和一致性。
数据分析与挖掘是大数据价值体现的关键,软件技术提供了丰富的算法库和可视化工具,帮助用户从数据中发现规律、洞察趋势,在数据分析领域,统计学方法、机器学习算法、深度学习模型等被广泛应用,Python语言及其生态系统(如Pandas、NumPy、Scikit-learn、TensorFlow)成为数据科学的主流工具,支持从数据探索、模型训练到结果部署的全流程,大数据可视化工具(如Tableau、Power BI、ECharts)将复杂的数据转化为直观的图表和仪表盘,使决策者能够快速理解数据内涵,在垂直行业中,大数据分析技术展现出巨大价值:在金融领域,通过用户行为分析和信用风险评估,实现精准营销和风险控制;在医疗领域,通过基因组数据分析、疾病预测模型,辅助临床诊断和新药研发;在零售领域,通过消费者行为分析、库存优化模型,提升供应链效率和用户体验。
大数据技术的应用离不开软件平台和工具的支撑,目前市场上有多种成熟的大数据技术栈供企业选择,以下是常见大数据技术及其应用场景的对比:
| 技术类别 | 代表技术/工具 | 核心功能 | 典型应用场景 |
|---|---|---|---|
| 分布式存储 | HDFS、MinIO | 高容错、高扩展的大数据存储 | 日志存储、非结构化数据存储 |
| 分布式计算 | MapReduce、Spark | 并行处理海量数据 | 批量数据处理、机器学习训练 |
| 流计算 | Flink、Storm | 实时数据流处理 | 实时监控、实时推荐、金融风控 |
| NoSQL数据库 | MongoDB、Redis | 高性能、灵活的数据存储 | 社交网络、缓存、物联网数据存储 |
| 数据仓库 | Hive、ClickHouse | 大数据查询和分析 | 商业智能、报表分析 |
| 机器学习平台 | TensorFlow、PyTorch | 深度学习模型训练和部署 | 图像识别、自然语言处理、预测分析 |
| 数据可视化 | Tableau、Power BI | 数据可视化展示和交互 | 决策支持、业务监控 |
在大数据技术落地的过程中,企业也面临着诸多挑战,首先是数据质量问题,多源异构数据的整合、清洗和标准化工作复杂且耗时;其次是技术选型难题,不同技术栈各有优劣,企业需根据业务需求和数据特点选择合适的工具;再次是人才短缺,既懂业务又懂技术的复合型数据人才供不应求;最后是数据安全与隐私保护问题,随着《数据安全法》《个人信息保护法》等法规的实施,企业在数据采集、存储和使用过程中需严格遵守合规要求,为应对这些挑战,企业需要建立完善的数据治理体系,加强人才培养和技术投入,同时采用安全加密、访问控制等技术手段保障数据安全。
展望未来,软件技术与大数据技术的融合将更加深入,人工智能与大数据的结合将推动智能分析向自动化、自主化方向发展,AutoML(自动机器学习)技术将降低模型开发门槛;边缘计算与大数据的结合将实现数据的就近处理,减少网络延迟,满足物联网、自动驾驶等实时场景需求;区块链技术将为大数据提供可信的存储和共享机制,解决数据确权和信任问题,随着量子计算、6G等前沿技术的发展,大数据处理能力将迎来新的突破,为人类社会带来更多创新应用。
相关问答FAQs:
Q1:大数据技术与传统数据处理技术的主要区别是什么?
A1:大数据技术与传统数据处理技术在数据规模、处理方式和技术架构上存在显著差异,大数据处理的数据量通常达到TB、PB甚至EB级别,而传统数据处理多集中在GB级别;大数据具有高多样性(结构化、非结构化数据混杂)、高 velocity(实时数据流)和低价值密度等特点,传统技术难以应对;大数据技术采用分布式架构(如Hadoop、Spark),通过横向扩展普通硬件实现高效处理,而传统技术多依赖垂直扩展的昂贵服务器,大数据技术更强调实时分析和价值挖掘,而传统技术更侧重事务处理和批量报表。
Q2:企业在实施数据大数据项目时,应如何选择合适的技术栈?
A2:企业选择大数据技术栈需综合考虑业务需求、数据特性、技术成本和团队能力等因素,明确项目目标:如果是实时流处理(如金融风控),可优先考虑Flink、Storm;如果是批量数据处理(如历史日志分析),Hadoop、Spark更为合适;评估数据类型:结构化数据可选Hive、ClickHouse,非结构化数据(如文本、图像)需搭配HDFS和NoSQL数据库;考虑成本预算:开源技术(如Hadoop、Spark)成本较低但需自行维护,商业平台(如Snowflake、Databricks)提供全托管服务但费用较高;团队能力是关键,若团队熟悉Python生态系统,可优先选择Spark MLlib和TensorFlow,若擅长Java,则Flink、Hadoop可能是更优选择,建议从小规模试点开始,逐步验证技术方案的可行性和扩展性。