drone无人机遥控器作为操控无人机的核心设备,其功能、技术参数及使用体验直接关系到飞行安全与操作效率,现代无人机遥控器已从简单的信号收发工具发展为集通信、控制、显示、交互于一体的智能终端,其设计融合了人体工程学、无线通信技术、传感器集成及智能算法等多领域成果,以下从功能架构、核心技术、操作逻辑、使用场景及发展趋势等方面展开详细分析。

功能架构与核心组成
无人机遥控器通常由发射端、通信模块、控制单元、人机交互界面及电源系统五部分构成,发射端通过内置天线将控制信号转化为无线电波传输至无人机;通信模块采用2.4GHz、5.8GHz或更高频段(如Wi-Fi、图传专用频段),确保信号稳定与低延迟;控制单元包括摇杆、拨杆、按键等物理元件,将操作者的指令转化为电信号;人机交互界面涵盖屏幕、指示灯、振动反馈等,用于显示飞行状态、图传画面及预警信息;电源系统则以锂电池为主,兼顾续航与便携性。
以主流消费级遥控器为例,其物理布局多遵循“双摇杆+多功能按键”设计:左摇杆控制油门(升降)和方向(偏航),右摇杆控制俯仰(前后)和横滚(左右),摇杆行程通过霍尔传感器精确采集,实现线性操控;拨杆用于切换飞行模式(如GPS模式、运动模式)、返航等功能;多功能按键则支持相机拍照、录像、参数调节等操作,高端遥控器还配备可编程按键,用户可根据习惯自定义功能,提升操作效率。
核心技术参数解析
-
通信技术与距离
遥控器与无人机的通信依赖无线传输协议,主流包括DJI的OcuSync、大疆Lightbridge、WiFi及传统FHSS(跳频扩频),OcuSync 3.0等技术支持10km以上图传距离,抗干扰能力较强;WiFi遥控器成本较低,但传输距离通常限制在1-2km,且易受环境干扰,实际通信距离受地形、电磁环境、天线增益等因素影响,开阔环境下的理论值与实际值可能存在30%-50%的差异。 -
操控精度与延迟
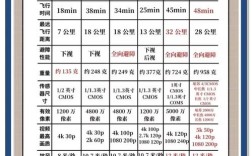
操控精度取决于摇杆传感器的分辨率(如霍尔传感器精度达0.001°)及算法优化,高端遥控器的信号延迟可低至30ms以内,接近实时响应;而入门级产品延迟可能超过100ms,影响复杂环境下的飞行稳定性,遥控器的刷新率(通常50-100Hz)越高,指令传输越连续,无人机姿态控制越平滑。 (图片来源网络,侵删)
(图片来源网络,侵删) -
兼容性与扩展性
部分遥控器支持跨平台兼容,如DJI的RC-N1可适配多款无人机型号;而专业级遥控器(如DJI Smart Controller)内置操作系统,支持第三方App扩展,实现地图导航、航点规划等高级功能,扩展性还体现在接口类型上,USB-C、HDMI、MicroSD等接口可连接外部设备,满足数据传输与外接显示需求。 -
续航与充电
遥控器电池容量通常在2000-5000mAh之间,续航时间约4-8小时,部分快充型号支持1.5小时内充满,为提升续航,部分产品配备省电模式(如屏幕自动调节亮度、非模块件休眠),或可更换电池设计,满足长时间作业需求。
操作逻辑与飞行模式适配
遥控器的操作逻辑需与无人机的飞行模式深度匹配,以实现精准控制,常见飞行模式及对应遥控器操作如下表所示:
| 飞行模式 | 遥控器操作逻辑 | 适用场景 |
|---|---|---|
| GPS模式 | 左摇杆中位悬停,摇杆幅度控制速度;自动悬停时轻微修正位置 | 新手练习、航拍 |
| 运动模式 | 操杆响应更灵敏,最大速度提升,关闭部分辅助功能 | 高速飞行、敏捷操作 |
| 手动模式 | 完全依赖遥控器操控,无自动平衡功能 | 专业竞速、特技飞行 |
| 航点模式 | 通过遥控器设置航点,无人机自动规划路径 | 自动巡检、测绘 |
| 跟随模式 | 拨杆切换跟随模式,无人机自动保持与目标距离 | 运动拍摄、户外追踪 |
部分遥控器支持“双控模式”,即两台遥控器分别控制无人机与云台,实现协同操作,适用于复杂拍摄场景。

使用场景与行业应用
-
消费级应用
摄影爱好者通过遥控器实现航拍构图、运镜控制,大疆等品牌遥控器内置的“大师镜头”功能可自动完成环绕、渐远等复杂动作;航模玩家则通过遥控器竞速,FPV(第一人称视角)遥控器搭配VR眼镜,带来沉浸式飞行体验。 -
行业级应用
- 农业植保:遥控器控制无人机精准喷洒农药,支持流量调节、变量喷洒,作业效率达人工的50倍以上。
- 物流运输:在偏远地区,遥控器引导无人机完成医疗物资、快递配送,需克服复杂地形与气象条件。
- 巡检监测:电力、石油行业通过遥控器操控无人机巡检线路、管道,红外热成像功能可实时识别设备故障。
-
特殊环境应用
在极端环境(如高温、高海拔、强电磁干扰)下,工业级遥控器采用加固外壳、抗干扰天线及宽温设计,确保稳定工作,消防救援用遥控器支持图传信号穿透烟雾,辅助救援人员实时掌握火场情况。
发展趋势与技术挑战
-
智能化升级
人工智能技术正逐步融入遥控器,如AI辅助操作(自动避障、悬停稳定)、语音控制(“上升”“拍照”等指令识别)、手势操控等,降低操作门槛,部分高端遥控器已具备学习能力,可根据用户习惯自动优化操控灵敏度。 -
轻量化与模块化
为提升便携性,遥控器趋向小型化(如折叠设计),模块化设计(可拆卸摇杆、屏幕)也受到关注,用户可根据需求配置功能模块,平衡性能与成本。 -
安全性与可靠性
随着无人机数量增加,遥控器的抗干扰、防丢失功能愈发重要,DJI的“双频段通信”技术可自动切换频段避开干扰;失控返航、低电量自动提醒等功能则大幅降低飞行风险。 -
技术挑战
高频谱资源占用与通信延迟仍是行业痛点,未来需通过6G、卫星通信等技术提升传输距离与速度;遥控器的续航能力需进一步突破,以满足长时间作业需求。
相关问答FAQs
Q1:无人机遥控器与手机App控制有何区别?
A:遥控器与手机App控制的核心区别在于操控精度、延迟与功能扩展性,遥控器采用专用通信协议与物理摇杆,操控延迟更低(50ms)、精度更高(支持复杂手势与精细调节),且抗干扰能力强,适合专业飞行;而手机App依赖WiFi或蓝牙,延迟较高(100-300ms),易受信号干扰,但便携性强,适合入门级用户进行简单操作,遥控器通常支持更多自定义功能与外接设备(如VR眼镜),而手机App功能受限于系统性能。
Q2:如何选择适合自己的无人机遥控器?
A:选择遥控器需综合考虑无人机型号、使用场景及预算:① 兼容性:优先选择与无人机品牌匹配的遥控器(如大疆无人机适配DJI遥控器),确保功能完整;② 操控需求:新手可选择简化功能、带自稳模式的遥控器,专业用户则需关注精度、延迟与可编程按键;③ 场景适配:航拍需重视图传清晰度与防抖功能,竞速飞行需优先考虑低延迟与轻量化设计;④ 预算:消费级遥控器价格多在500-3000元,行业级产品可达万元以上,需根据需求平衡性能与成本。