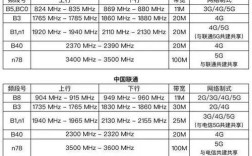
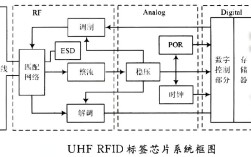
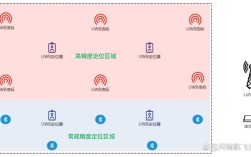
数据挖掘与语义分析技术的结合正在深刻改变各行各业从海量数据中提取价值的方式,数据挖掘作为从大量数据中通过算法搜索隐藏于信息知识的技术,其核心在于模式识别与预测建模;而语义分析技术则专注于理解人类语言背后的真实含义,包括情感倾向、实体关系、意图识别等,两者的融合使得机器不仅能处理数据的“量”,更能理解数据的“质”,从而在商业智能、舆情监控、医疗健康等领域展现出巨大潜力。

从技术原理来看,数据挖掘通常包括数据预处理、特征提取、模型构建与评估等环节,预处理阶段涉及数据清洗、去噪、标准化,确保分析对象的质量;特征提取则通过统计学方法或降维技术(如PCA)识别关键变量;模型构建阶段会根据任务类型选择算法,如分类(决策树、SVM)、聚类(K-means、DBSCAN)或关联规则(Apriori),而语义分析技术以自然语言处理(NLP)为基础,通过分词、词性标注、句法分析等步骤将非结构化文本转化为结构化数据,再利用词向量(Word2Vec、BERT)、情感词典、主题模型(LDA)等工具挖掘语义信息,BERT模型通过双向Transformer编码器能够捕捉上下文语境,准确识别“苹果”在“吃苹果”和“苹果公司”中的不同含义,这是传统数据挖掘难以企及的深度。
两者的协同工作流程可概括为三个阶段:首先是数据融合,将结构化数据(如用户年龄、购买记录)与非结构化数据(如评论、客服对话)整合为统一数据集;其次是语义增强,通过语义分析技术为非结构化数据打上语义标签,如将“物流太慢了”标注为“负面情感-物流体验差”;最后是联合建模,将语义特征与传统数值特征共同输入数据挖掘模型,提升预测精度,在电商推荐系统中,数据挖掘可分析用户的购买历史和浏览行为,而语义分析则能解读用户评论中的潜在需求(如“屏幕太亮”可能暗示对护眼功能的需求),两者结合可实现更精准的个性化推荐。
技术实现层面,语义分析为数据挖掘提供了多维度的特征空间,传统数据挖掘依赖数值型或类别型特征,而语义分析可生成情感极性、主题分布、实体链接等高维语义特征,以舆情分析为例,通过LDA主题模型可从社交媒体数据中提取“产品质量”“售后服务”等主题,再结合情感分析计算各主题的情感倾向,最终通过聚类算法识别舆情热点,知识图谱技术作为语义分析的重要分支,能构建实体间的语义网络,为数据挖掘提供关系型特征,在金融风控领域,知识图谱可关联企业股东、法人、上下游合作伙伴的关系,与传统财务数据结合后,决策树模型能更准确地识别欺诈风险。
实际应用场景中,这种技术组合的价值尤为突出,在医疗领域,电子病历中的非结构化文本包含大量诊断信息,语义分析技术可提取症状、疾病、药物的实体关系,数据挖掘则能通过关联规则分析药物组合的疗效,辅助临床决策,某医院通过分析10万份病历,发现“阿司匹林+氯吡格雷”与“消化道出血”的强关联,为用药安全提供依据,在金融行业,智能客服系统利用语义分析理解用户意图(如“查询信用卡账单”),数据挖掘则根据用户历史行为预测其潜在需求(如推荐分期还款服务),将问题解决率提升40%,制造业中,通过语义分析解析设备故障日志中的文本描述,数据挖掘可建立故障预测模型,将设备停机时间减少30%。
技术融合仍面临诸多挑战,首先是数据异构性问题,结构化数据与非结构化数据的格式差异增加了特征对齐的难度,其次是语义理解的深度限制,当前NLP模型对隐喻、反讽等复杂语言现象的识别准确率不足,可能影响数据挖掘的质量,计算资源消耗巨大,BERT等模型训练需要高性能GPU支持,中小企业难以承担,为解决这些问题,轻量化模型(如DistilBERT)和迁移学习技术正在兴起,通过预训练+微调的方式降低计算成本;而多模态数据融合技术则尝试将文本、图像、语音统一到同一语义空间,实现更全面的数据挖掘。
未来发展趋势将聚焦于三个方向:一是实时化处理,流式数据挖掘与增量语义分析的结合,将满足金融反欺诈、实时舆情监控等场景的毫秒级响应需求;二是可解释性增强,通过注意力机制可视化语义特征对数据挖掘模型决策的影响,解决“黑箱”问题;三是跨领域知识迁移,预训练语言模型(如GPT)在不同领域数据上的微调,将大幅降低语义分析的数据依赖性,在法律领域,通过预训练模型理解法律文书中的专业术语,数据挖掘可快速案例相似度匹配,将律师检索效率提升90%。
相关问答FAQs:
-
问:数据挖掘与语义分析技术的主要区别是什么?
答:数据挖掘侧重于从结构化或半结构化数据中发现统计规律和模式,如聚类、分类等,主要处理数值型和类别型数据;语义分析则专注于理解非结构化文本的深层含义,包括情感、意图、实体关系等,依赖NLP技术实现语言层面的解读,前者关注“数据本身的关联”,后者关注“语言背后的逻辑”,两者结合才能实现从“数据”到“知识”的跨越。 -
问:中小企业如何低成本应用数据挖掘与语义分析技术?
答:中小企业可采用以下策略降低成本:一是利用开源工具(如Python的NLTK、Scikit-learn)替代商业软件;二是采用云服务按需付费(如阿里云NLP、AWS Comprehend),避免硬件投入;三是聚焦特定场景,先从简单的情感分析、关键词提取入手,而非追求复杂的全流程系统;四是借助预训练模型(如BERT-base)进行微调,减少标注数据需求,餐饮企业可通过开源LDA模型分析评论主题,结合Excel数据挖掘功能识别菜品改进方向,实现低成本智能化。