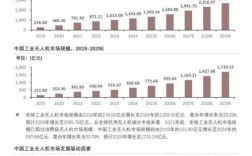
主要涉及执照类型、申请条件、培训考核、有效与管理及违规处罚等方面,旨在规范无人机驾驶行为,保障空域安全与公共秩序,以下是具体规定内容:
执照类型与适用范围
根据中国民用航空局(CAAC)规定,无人机驾照分为三种类型,分别对应不同重量和用途的无人机操作:
- 驾驶员执照(视距内驾驶员):适用于在视距内(距操作者水平距离≤500米、相对高度≤120米)操作的空机重量≤4kg的无人机,或超4kg但符合运行安全要求的轻型无人机,主要应用于航拍、短距离巡检等场景。
- 机长执照(超视距驾驶员):适用于超视距(超出视距范围)运行的无人机,或空机重量>4kg的轻型无人机、微型无人机在特定复杂环境下的操作,需掌握航线规划、应急处置等技能,常用于物流运输、农林植保等专业领域。
- 教员执照:适用于培训驾驶员或机长的教员,需具备机长执照及一定教学经验,可指导学员考核与日常训练。
申请条件
不同执照类型的申请条件存在差异,需满足以下基本要求:
- 年龄限制:年满16周岁(未满18周岁需监护人同意),教员执照需年满18周岁。
- 健康要求:无妨碍安全操作的疾病(如色盲、癫痫、心血管疾病等),需提供县级以上医院出具的体检证明。
- 无犯罪记录:无危害民用航空安全的违法犯罪记录,需公安机关出具相关证明。
- 培训经历:需通过CAAC授权的无人机培训机构完成规定学时的理论培训(驾驶员≥40学时,机长≥60学时)和实操培训(驾驶员≥44学时,机长≥56学时)。
培训与考核内容
培训考核分为理论考试和实操飞行考试两部分,均需通过CAAC组织的统一考核:
- 理论考试:包括民航法规、无人机原理、气象知识、空域规则、应急处置等,题型为选择题和判断题,满分100分,80分及以上为合格。
- 实操飞行考试:
- 驾驶员:考核起飞降落、悬停、八字航线、应急返航等基础操作,要求在指定区域内完成精准控制。
- 机长:增加航线规划、超视距飞行、模拟故障处置(如失联、低电量)等考核内容,需独立完成复杂场景任务。
- 教员执照:额外考核教学能力、教案编写及学员评估方法,需通过试讲评审。
执照有效性与管理
- 有效期:驾驶员和机长执照有效期为3年,教员执照有效期为2年,到期前需申请换证,完成不少于20学时的复训考核。
- 年度检查:执照持有人需每年通过“民用无人机综合管理平台”完成在线年度注册,未注册者执照自动失效。
- 信息变更:姓名、身份证号等个人信息变更时,需在30日内提交变更申请,更新执照信息。
- 注销情形:出现以下情况之一,CAAC将注销执照:健康条件不适宜操作、严重违规操作导致事故、提供虚假材料申领执照等。
违规处罚
对无证操作、超范围飞行或违规行为,CAAC将依法处罚:
- 无证操作:由民航监管部门责令停止操作,处500元以上2000元以下罚款;造成事故的,依法追究刑事责任。
- 超范围飞行:如驾驶员超视距操作或机长违规进入禁飞区,处1000元以上5000元以下罚款,并暂扣执照3-6个月。
- 虚假信息:通过伪造体检证明、培训记录等申领执照的,撤销执照并处2000元以上10000元以下罚款,3年内不得重新申请。
无人机分类与执照对应关系
为明确操作权限,CAAC根据无人机重量和用途划分管理类别,具体对应关系如下:
| 无人机类型 | 空机重量/起飞重量 | 所需执照 | 适用场景 |
|---|---|---|---|
| 微型无人机 | ≤4kg | 无需执照(需实名登记) | 个人娱乐、低风险航拍 |
| 轻型无人机 | 4kg<重量≤25kg | 驾驶员执照 | 短距离巡检、小型航拍 |
| 小型无人机 | 25kg<重量≤150kg | 机长执照 | 物流运输、农林植保 |
| 大型无人机 | >150kg | 机长执照(特殊审批) | 高难度作业、专业测绘 |
相关问答FAQs
Q1:个人购买无人机用于娱乐飞行,是否需要考取驾照?
A:根据规定,空机重量≤4kg的微型无人机(如DJI Mini系列)用于个人娱乐飞行无需驾照,但需在“民用无人机综合管理平台”实名登记,并遵守视距内飞行、避开机场和人口密集区等安全要求,若无人机重量>4kg或用于商业活动(如航拍收费),则必须对应考取驾驶员或机长执照。
Q2:驾照过期后如何换证?需要重新参加全部培训和考试吗?
A:执照到期前6个月内,持有人需登录CAAC授权的无人机执照管理系统提交换证申请,完成以下步骤:① 完成20学时复训(含理论更新和实操复习);② 通过换证考核(理论考试为抽题,实操考核为重点项目抽查);③ 提交近期体检证明和无犯罪记录证明,通过考核后,CAAC将更新执照有效期,无需重新参加全部培训和考试,若逾期超过1年未换证,需按新申请流程重新考取执照。