大数据技术与应用是指通过采集、存储、处理、分析和可视化海量、多样化、高速增长的数据,从中提取有价值信息并应用于实际业务领域的技术体系与实践过程,其核心在于突破传统数据处理工具的能力局限,通过分布式计算、机器学习等先进技术,实现对数据价值的深度挖掘,助力决策优化、效率提升和模式创新。

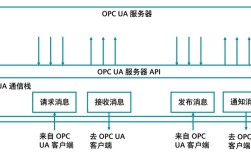
从技术层面看,大数据技术体系涵盖多个关键环节,数据采集环节涉及物联网传感器、社交媒体、业务系统等多源异构数据的接入,常用工具包括Flume、Kafka等,能够实现高并发、低延迟的数据汇聚,数据存储环节需应对结构化数据(如数据库表)、半结构化数据(如JSON、XML)和非结构化数据(如文本、图像、视频)的多样化需求,分布式文件系统(如HDFS)、NoSQL数据库(如MongoDB、Cassandra)和NewSQL数据库(如TiDB)成为主流选择,通过横向扩展提升存储容量和读写性能,数据处理环节依赖分布式计算框架,如Hadoop MapReduce实现批处理计算,Spark支持内存计算提升实时性,Flink则专注于流处理,满足毫秒级响应需求,数据分析环节通过数据仓库(如Hive)、数据湖(如Delta Lake)构建数据资产,结合统计学方法、机器学习算法(如分类、聚类、回归)和深度学习模型,从数据中挖掘规律、预测趋势,数据可视化环节则通过Tableau、Power BI等工具将分析结果转化为图表、仪表盘,实现直观呈现。
大数据技术的应用已渗透到各行各业,在金融领域,银行通过分析用户交易数据构建风控模型,实时识别欺诈行为;保险公司利用车险驾驶行为数据定价,实现个性化保费,零售行业通过用户消费画像实现精准营销,优化库存管理,例如某电商平台通过分析用户浏览和购买数据,将推荐准确率提升30%,医疗健康领域,基因测序大数据助力疾病预测和个性化治疗,医院通过电子病历数据分析优化诊疗方案,制造业中,工业物联网设备实时采集生产线数据,通过预测性维护减少设备故障率,降低停机损失,城市治理方面,交通大数据信号灯控制系统缓解拥堵,环保部门通过空气质量数据溯源污染源,互联网企业更是大数据应用的典型代表,搜索引擎通过用户行为数据优化排序算法,短视频平台基于用户兴趣推荐内容,提升用户粘性。
大数据技术的核心价值在于从“数据”到“信息”再到“知识”的转化,其技术特点体现为“4V”:Volume(数据量大,从TB级跃升至PB、EB级)、Velocity(处理速度快,实时或近实时响应)、Variety(数据类型多样,结构化与非结构化数据并存)、Value(价值密度低,需通过深度分析提炼价值),为支撑这些特点,技术架构逐渐从传统的数据仓库向数据中台演进,通过统一的数据治理和共享机制,打破数据孤岛,提升复用效率。
大数据应用也面临挑战,数据质量问题(如噪声、缺失值)会影响分析结果准确性;数据安全与隐私保护需通过加密技术、访问控制和合规监管(如GDPR、个人信息保护法)保障;技术复杂度高要求团队具备跨学科能力(如计算机、统计学、业务领域知识);数据伦理问题也需重视,避免算法偏见导致的不公平决策。

随着技术发展,大数据与人工智能、云计算、边缘计算的融合日益深入,云原生大数据平台(如AWS EMR、阿里云E-MapReduce)降低部署门槛,边缘计算实现就近数据处理,5G技术提升数据传输效率,这些趋势将进一步拓展大数据的应用边界,推动社会向数据驱动型模式转型。
相关问答FAQs
Q1:大数据技术与传统数据处理的主要区别是什么?
A1:区别主要体现在四个方面:一是数据规模,传统数据处理通常处理GB级数据,而大数据处理PB级以上;二是技术架构,传统依赖单机数据库,大数据采用分布式架构;三是数据类型,传统以结构化数据为主,大数据涵盖文本、图像等非结构化数据;四是处理时效,传统以批处理为主,大数据支持实时流处理,大数据更强调从海量数据中挖掘潜在价值,而非简单的数据查询和统计。
Q2:企业实施数据大数据应用需要具备哪些基础条件?
A2:企业需具备三个核心基础:一是数据基础,包括完善的数据采集机制、规范的数据治理体系和高质量的数据资产;二是技术基础,需搭建分布式存储、计算平台(如Hadoop、Spark集群)及配套工具链,或选择云服务降低运维成本;三是人才基础,需要数据工程师(负责数据架构搭建)、数据分析师(负责业务解读)和数据科学家(负责算法建模)的协作团队,企业高层需具备数据驱动决策的理念,推动跨部门数据共享与应用落地。