特斯拉作为新能源汽车领域的领军企业,其产品生态不仅涵盖智能汽车,还通过跨界布局不断拓展用户的生活场景,近年来,特斯拉推出的“赠品无人机”及其配套APP,成为连接汽车与空中影像体验的创新尝试,为用户带来了全新的智能交互视角,这一组合不仅延续了特斯拉在科技整合与用户体验上的优势,也展现了其在消费级无人机领域的探索方向。

特斯拉赠品无人机的定位与核心功能
特斯拉赠品无人机并非专业级航拍设备,而是作为车主福利或购车礼包的附加产品,主打轻量化、易操作与智能联动,其设计初衷是让用户能够通过空中视角记录生活、辅助用车,甚至与特斯拉汽车形成场景互补。
硬件特性
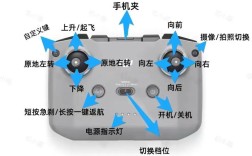
根据曝光的参数,该无人机可能采用折叠机身设计,重量控制在500克以内,便于收纳和携带,续航方面,预计单次飞行时间为25-30分钟,搭载4K高清摄像头,支持电子防抖和三轴机械增稳,确保画面稳定性,可能具备避障传感器(如视觉+红外双模系统),可在低光环境下安全飞行。
与特斯拉汽车的联动场景
作为“赠品”,其核心价值在于与特斯拉生态的深度融合:
- 自动跟随模式:通过APP与汽车蓝牙/Wi-Fi连接,无人机可自动跟随车辆行驶,拍摄行驶过程中的动态画面,适合自驾游或车辆测试场景。
- 停车场寻车辅助:在大型停车场,用户可通过APP控制无人机升空定位车辆,解决“找不到车”的痛点。
- 车载能源共享:部分版本可能支持与特斯拉车辆充电口连接,利用车辆电池为无人机应急充电,延长使用时间。
配套APP的核心功能与交互设计
特斯拉无人机APP是操控设备的中枢,其界面设计与操作逻辑延续了特斯拉产品极简、智能的风格,同时针对无人机场景进行了专属优化。

APP界面与操作逻辑
| 功能模块 | 说明 |
|---|---|
| 实时图传 | 1080P/4K低延迟画面传输,支持分屏显示(同时查看航拍画面与汽车状态数据)。 |
| 智能航点 | 在地图上预设飞行路径,无人机自动按轨迹拍摄,适合全景录制或巡检。 |
| 一键分享 | 可直接同步至特斯拉车机系统或社交媒体,生成带车辆标识的短视频。 |
| 安全模式 | 包含地理围栏(限制飞行区域)、返航电量提醒、失联自动悬停等功能。 |
与其他特斯拉产品的生态联动
- 与特斯拉车机互联:航拍画面可投射至中控屏, passengers 在车内实时观看空中视角,增强乘坐体验。
- 能源管理整合:APP可显示无人机与车辆的电量状态,建议在车辆充电时同步为无人机充电,优化能源使用效率。
- 数据同步:航拍素材自动上传至特斯拉用户账户,支持云端存储与跨设备调取。
用户体验与潜在挑战
优势
- 低门槛操作:通过APP的一键起飞、智能跟随等功能,即使新手也能快速上手。
- 场景化创新:与汽车联动的功能解决了传统无人机使用场景单一的痛点,强化了“特斯拉生活方式”的标签。
- 品牌溢价:作为特斯拉生态的一部分,其设计语言与产品调性与汽车高度统一,提升了用户对品牌的认同感。
局限性
- 性能限制:作为赠品,其硬件参数(如抗风能力、图传距离)可能弱于专业无人机,不适合复杂环境使用。
- 法规风险:不同地区对无人机的飞行高度、区域限制严格,用户需遵守当地法规,避免违规飞行。
- 依赖生态:部分高级功能需与特斯拉汽车绑定使用,对于非车主用户价值降低。
市场意义与未来展望
特斯拉赠品无人机的推出,本质是通过“硬件+软件”的组合,进一步巩固其“科技生活服务商”的定位,它以低成本方式让用户接触无人机技术,培养潜在市场;通过数据收集(如飞行习惯、航拍内容偏好),为未来可能的专业级无人机或智能出行设备积累经验。
特斯拉或可能基于此推出付费升级服务,如更高清的摄像头模块、与自动驾驶系统联动的“自动巡检”功能,甚至探索无人机在物流配送、车辆救援等领域的应用,逐步构建“陆空一体”的智能出行网络。
相关问答FAQs
Q1:特斯拉赠品无人机是否需要额外购买订阅服务?
A:该无人机作为购车赠品或礼包附件,基础功能(如遥控飞行、图传、智能跟随)无需订阅,但未来可能推出增值服务,如4K云端存储、高级航点编辑等,届时可能需要付费订阅,建议用户关注特斯拉官方APP的更新通知,以获取最新服务政策。
Q2:飞行无人机时需要注意哪些法规问题?
A:用户需严格遵守当地无人机管理法规,
- 在多数地区,无人机需实名登记,并避开机场、军事区、人群密集区等禁飞区域;
- 飞行高度通常限制为120米以下,且需在视距范围内操作;
- 部分国家要求购买第三方责任险,建议在首次飞行前通过当地航空管理部门官网查询具体规定,或使用APP内置的“合规助手”功能(如有)获取实时提醒。