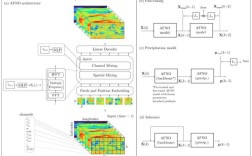
这是一种在人工智能,特别是大语言模型 领域中非常前沿和重要的技术。FlexibleLoM 是一种用于高效管理大模型运行时内存的动态内存分配技术,它通过“按需分配”和“动态调整”内存块,极大地降低了运行大模型所需的显存开销。

下面我们从几个方面来深入理解它。
核心问题:为什么需要 FlexibleLoM?
要理解 FlexibleLoM 的价值,首先要明白它解决了什么核心问题,这个问题的根源在于大模型的巨大内存占用。
-
传统静态内存分配的困境:
- 模型大小:像 GPT-3、PaLM 或 LLaMA 这样的大模型,其参数量可达数十亿甚至数千亿,每个参数通常用 16 位(FP16)或 32 位(FP32)浮点数表示。
- 内存需求:一个 700 亿参数的 FP16 模型,仅模型参数本身就需要
700B * 2 bytes ≈ 1.4 TB的显存,这对于绝大多数消费级显卡(如 RTX 4090 只有 24GB 显存)来说是完全无法承受的。 - KV Cache:在生成文本时,模型需要存储之前所有 token 的 Key 和 Value 向量,即 KV Cache,随着生成长度的增加,KV Cache 会持续增长,成为显存消耗的另一大元凶。
-
解决方案的演进:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 早期方案(如 ZeRO-Offload):将模型参数和优化器状态等卸载到速度慢得多的 CPU 内存或硬盘上,这虽然能降低显存占用,但会导致计算效率急剧下降,因为每次需要参数时都要从慢速内存中读取。
- 更优方案(如 PagedAttention / vLLM):引入了类似操作系统虚拟内存的“分页”机制,它将连续的 KV Cache 分割成固定大小的“页”,并动态地将这些页加载到显存中,不活跃的页可以被换出到 CPU 内存,这比全量卸载高效得多,但通常仍需要一个固定的、巨大的预分配池来容纳这些页。
- FlexibleLoM 的出现:它更进一步,不仅管理 KV Cache,还更灵活地管理模型本身的激活值和中间计算结果,它的核心思想是:内存不是预先分配好的固定块,而是根据计算图的需求,动态地、按需地分配和释放。
FlexibleLoM 的工作原理
FlexibleLoM 的核心可以概括为 “动态内存池” 和 “细粒度管理”。
a. 动态内存池
想象一下你的显存是一个巨大的水池,传统的做法是,在开始计算前,就先从水池里舀出好几个大桶(预分配内存),然后在整个计算过程中都使用这些桶,即使很多时候桶里是空的。
FlexibleLoM 的做法是:
- 不预分配大块内存:它只保留一个相对较小的“工作池”在显存中。
- 按需申请:当计算图中的某个操作需要临时存储数据(某个中间层的激活值)时,它才从工作池中申请一小块刚好够用的内存。
- 用完即还:当这个计算步骤完成,这块内存就立刻被释放回工作池,供其他任务使用。
这种方式可以最大化地复用显存,避免了静态分配中常见的内存浪费。

b. 细粒度管理
这是 FlexibleLoM 与传统技术最关键的区别之一,它不是以整个层或整个模块为单位来管理内存,而是以更小的单位(如张量或算子)进行管理。
- 传统管理:计算第
L层时,需要把整个第L层的输入、输出、中间激活值都加载到显存中,即使这些数据中只有一小部分在下一步会被用到。 - FlexibleLoM 管理:它能精确地追踪到,在计算第
L层的某个特定算子时,只需要A和B两个小张量,并产生C这个小张量,它会只加载A和B,计算完得到C后,立即释放A和B的内存。
这种“即用即取,用完即弃”的策略,使得内存的周转率极高,从而能够以远小于模型总大小的显存运行大模型。
c. 与 PagedAttention 的关系
FlexibleLoM 和 PagedAttention(vLLM 的核心技术)经常被一起提及,它们关系密切,但侧重点不同:
- PagedAttention:专注于KV Cache的分页管理,它解决了生成长度不确定导致的 KV Cache 动态增长问题。
- FlexibleLoM:范围更广,它不仅管理 KV Cache,还管理模型在推理过程中产生的所有临时激活值,可以说,PagedAttention 是 FlexibleLoM 思想在 KV Cache 上的一个具体应用。
主要优势
- 显著降低显存占用:这是最直接、最重要的优势,通过动态复用,显存利用率大大提高,使得在有限的显存(如 24GB GPU)上运行远超其容量的模型成为可能。
- 提高计算效率:相比于将数据卸载到 CPU 内存,FlexibleLoM 的一切操作都在高速的 GPU 显存中完成,避免了数据在 GPU 和 CPU 之间的频繁、低速传输,因此推理速度更快。
- 支持更长上下文:由于 KV Cache 管理更高效,并且有更大的可用内存空间,模型可以处理更长的输入序列,即支持更长的上下文窗口。
- 资源更灵活:不需要一次性为整个模型预留所有内存,可以根据实际的计算负载动态调整,使得资源分配更加合理。
挑战与缺点
尽管优势明显,FlexibleLoM 技术也面临一些挑战:
- 实现复杂度高:需要深入理解模型的计算图,并设计一套复杂的运行时内存管理系统,这通常需要与深度学习框架(如 PyTorch)进行深度集成,开发难度很大。
- 运行时开销:动态的内存分配和释放本身需要消耗一定的 CPU 时间进行调度和管理,如果管理不当,这个开销可能会成为性能瓶颈。
- 调试困难:内存的动态变化使得调试变得非常困难,当出现内存错误(如越界访问)时,很难追踪到问题的根源,因为内存布局在每次运行时都可能不同。
应用场景
FlexibleLoM 技术主要应用于对显存有严苛要求的场景:
- 大语言模型推理:这是最主要的应用场景,几乎所有现代的高效 LLM 推理框架(如 vLLM, TensorRT-LLM, DeepSpeed-Inference)都采用了类似 FlexibleLoM 的思想。
- 大规模模型微调:在微调大模型时,即使使用梯度检查点 等技术,内存压力依然巨大,FlexibleLoM 可以帮助在有限的硬件上完成微调任务。
- 多租户服务:在云服务中,一个 GPU 需要同时为多个用户请求服务,FlexibleLoM 可以更公平、高效地划分 GPU 显存资源。
FlexibleLoM 本质上是一种将现代操作系统虚拟内存管理思想,创造性地应用于深度学习模型推理中的技术。
它通过 “动态分配、按需使用、即时释放” 的核心原则,打破了传统静态内存分配对模型大小的限制,实现了对 GPU 显存资源的极致压榨,这使得在消费级硬件上运行和部署曾经遥不可及的千亿级大模型成为可能,是推动大模型走向普及和高效应用的关键技术之一,你可以把它理解为 GPU 显存的“共享单车”系统,而不是“私家车”系统,极大地提高了资源的利用率。