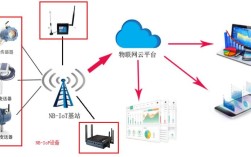
智能AI的实现依赖于多种核心技术的协同作用,这些技术涵盖了从数据基础到算法模型,再到应用落地的完整链条,机器学习是智能AI的基石,通过算法让计算机从数据中自动学习规律,无需显式编程,监督学习、无监督学习和强化学习是主要范式:监督学习利用标注数据训练模型(如分类、回归),无监督学习则从无标签数据中发现隐藏结构(如聚类、降维),强化学习通过与环境交互和奖励机制优化决策(如AlphaGo的自我对弈),深度学习作为机器学习的子集,通过多层神经网络模拟人脑结构,显著提升了AI的复杂模式识别能力,尤其在图像识别(CNN)、自然语言处理(RNN、Transformer)等领域取得突破。
自然语言处理(NLP)技术使AI能够理解和生成人类语言,包括文本分类、情感分析、机器翻译、问答系统等,其核心技术包括词嵌入(Word2Vec、GloVe)将文本转化为向量,以及Transformer模型(如BERT、GPT)通过自注意力机制捕捉上下文依赖关系,实现更精准的语言理解和生成,计算机视觉技术则赋予AI“看”的能力,通过图像分类、目标检测(如YOLO、Faster R-CNN)、图像分割等技术,让机器能够识别和解析图像内容,广泛应用于自动驾驶、医疗影像分析等领域。
知识图谱技术构建了结构化的语义网络,通过实体、关系和属性描述现实世界的知识,支持AI进行推理和问答(如智能客服、搜索引擎优化),多模态融合技术则整合文本、图像、语音等多种数据类型,实现跨模态的理解和生成(如图文描述生成、语音识别与语义结合的交互系统),强化学习与决策优化技术让AI在动态环境中自主学习最优策略,应用于机器人控制、资源调度等场景。
在工程落地层面,分布式计算与云计算技术提供了强大的算力支持,训练大规模模型需要GPU/TPU集群和分布式框架(如TensorFlow、PyTorch),边缘计算则将AI能力下沉到终端设备(如手机、物联网设备),降低延迟并保护数据隐私,数据预处理与特征工程技术确保输入数据的质量,包括数据清洗、归一化、特征选择等步骤,直接影响模型性能,模型压缩与优化技术(如剪枝、量化、蒸馏)则解决大模型部署的资源瓶颈,使其能在移动端或嵌入式设备运行。
以下是关键技术分类及应用示例的简要总结:
| 技术类别 | 核心技术/方法 | 典型应用场景 |
|---|---|---|
| 机器学习 | 监督学习、无监督学习、强化学习 | 预测分析、异常检测、游戏AI |
| 深度学习 | CNN、RNN、Transformer | 图像识别、语音识别、机器翻译 |
| 自然语言处理 | 词嵌入、BERT、GPT | 智能客服、文本生成、情感分析 |
| 计算机视觉 | 目标检测、图像分割、人脸识别 | 自动驾驶、医疗影像、安防监控 |
| 知识图谱 | 实体链接、关系抽取、推理引擎 | 智能问答、推荐系统、搜索引擎 |
| 多模态融合 | 跨模态注意力、图文对齐 | 理解、多模态交互 |
| 强化学习 | Q-learning、策略梯度 | 机器人控制、动态资源优化 |
| 工程化技术 | 分布式计算、模型压缩、边缘计算 | 大模型训练、移动端AI部署 |
相关问答FAQs:
-
问:智能AI与传统软件的主要区别是什么?
答:传统软件依赖人工编写的规则和逻辑,功能固定且难以适应复杂场景;智能AI通过数据驱动的机器学习模型自主学习规律,能够处理模糊、动态的问题,并随着数据积累持续优化性能,具备一定的泛化能力和适应性。 -
问:当前AI技术发展面临的最大挑战是什么?
答:当前AI技术面临的主要挑战包括:数据质量与隐私问题(需大量高质量标注数据且存在隐私泄露风险);模型可解释性不足(深度学习常被视为“黑箱”,难以解释决策过程);算力与能耗瓶颈(大模型训练需海量算力,成本高昂且不环保);以及伦理与安全问题(如算法偏见、滥用风险等),这些挑战需要跨学科协作和技术创新共同解决。